官方地址
RAG 学习
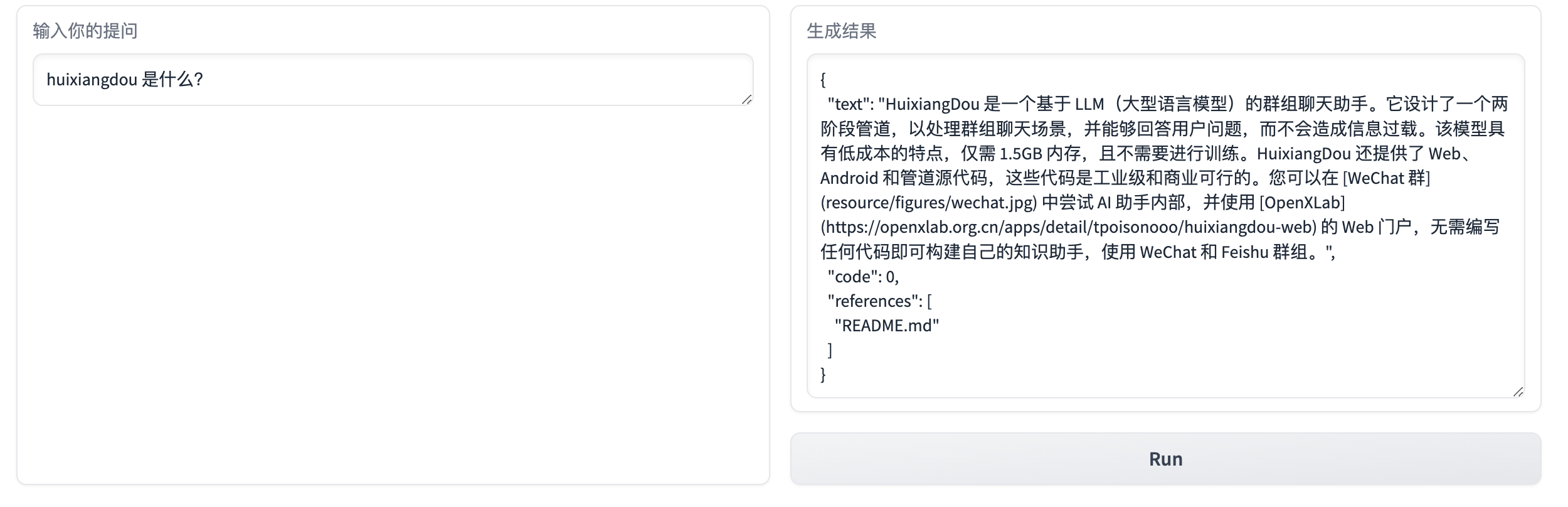
有了知识库后,怎样将我们『搜索的问题/代码』在『知识库』中找到『相关度最高的内容』?
答案是通过三个过程:
- Text Embeddings(文本向量化)
- Vector Stores(向量存储)
- Similarity Search(相似性搜索)
提取知识库特征,创建向量数据库。数据库向量化的过程应用到了 LangChain 的相关模块,默认嵌入和重排序模型调用的网易 BCE 双语模型,如果没有在 config.ini 文件中指定本地模型路径,茴香豆将自动从 HuggingFace 拉取默认模型。
在确定好语料来源后,运行下面的命令,创建 RAG 检索过程中使用的:
# 分别向量化知识语料、接受问题和拒绝问题中后保存到 workdir
python3 -m huixiangdou.service.feature_store --sample ./test_queries.json检索过程中,茴香豆会将输入问题与两个列表中的问题在向量空间进行相似性比较,判断该问题是否应该回答,避免群聊过程中的问答泛滥。确定的回答的问题会利用基础模型提取关键词,在知识库中检索 top K 相似的 chunk,综合问题和检索到的 chunk 生成答案。
基础作业
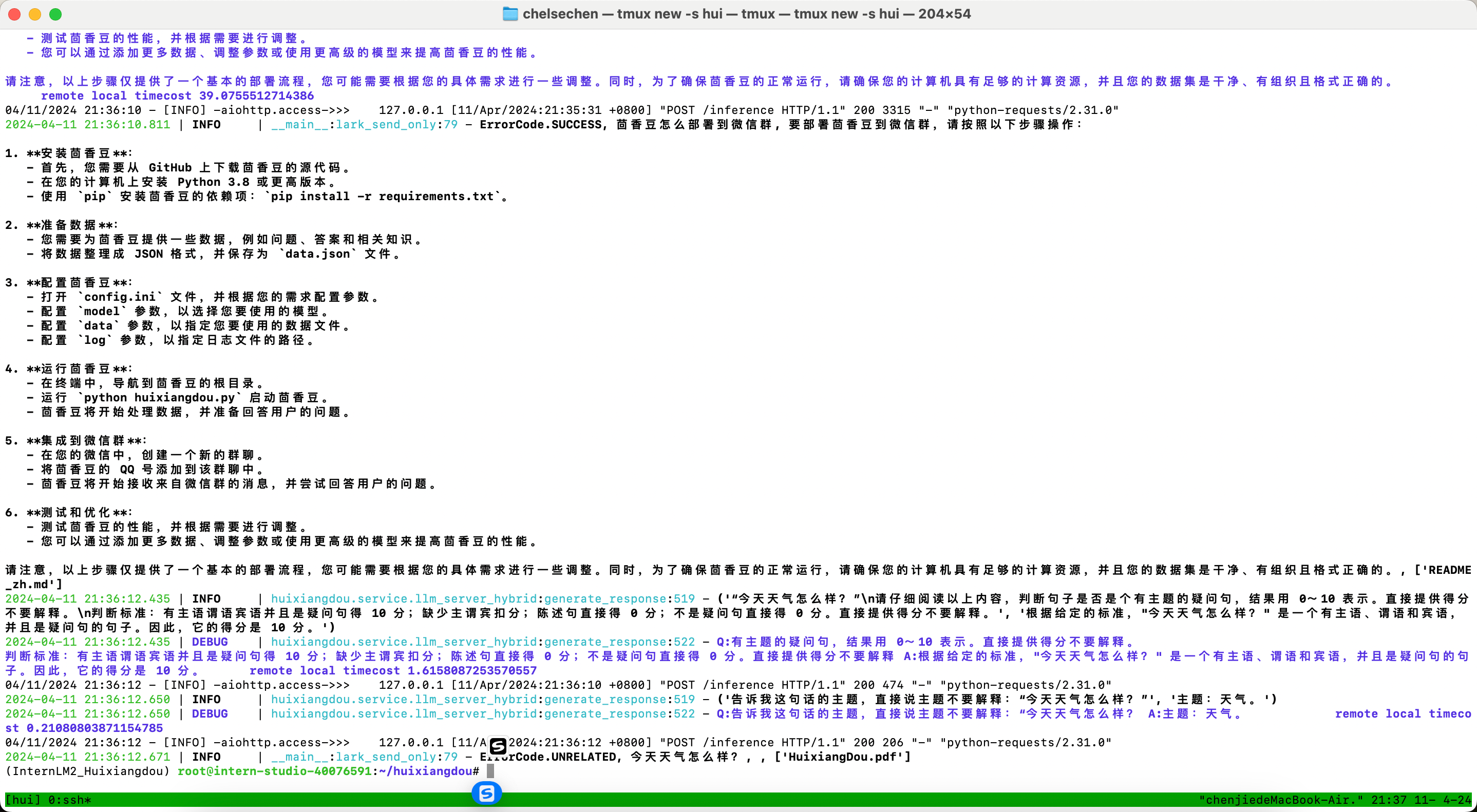
在 InternLM Studio 上部署茴香豆技术助手
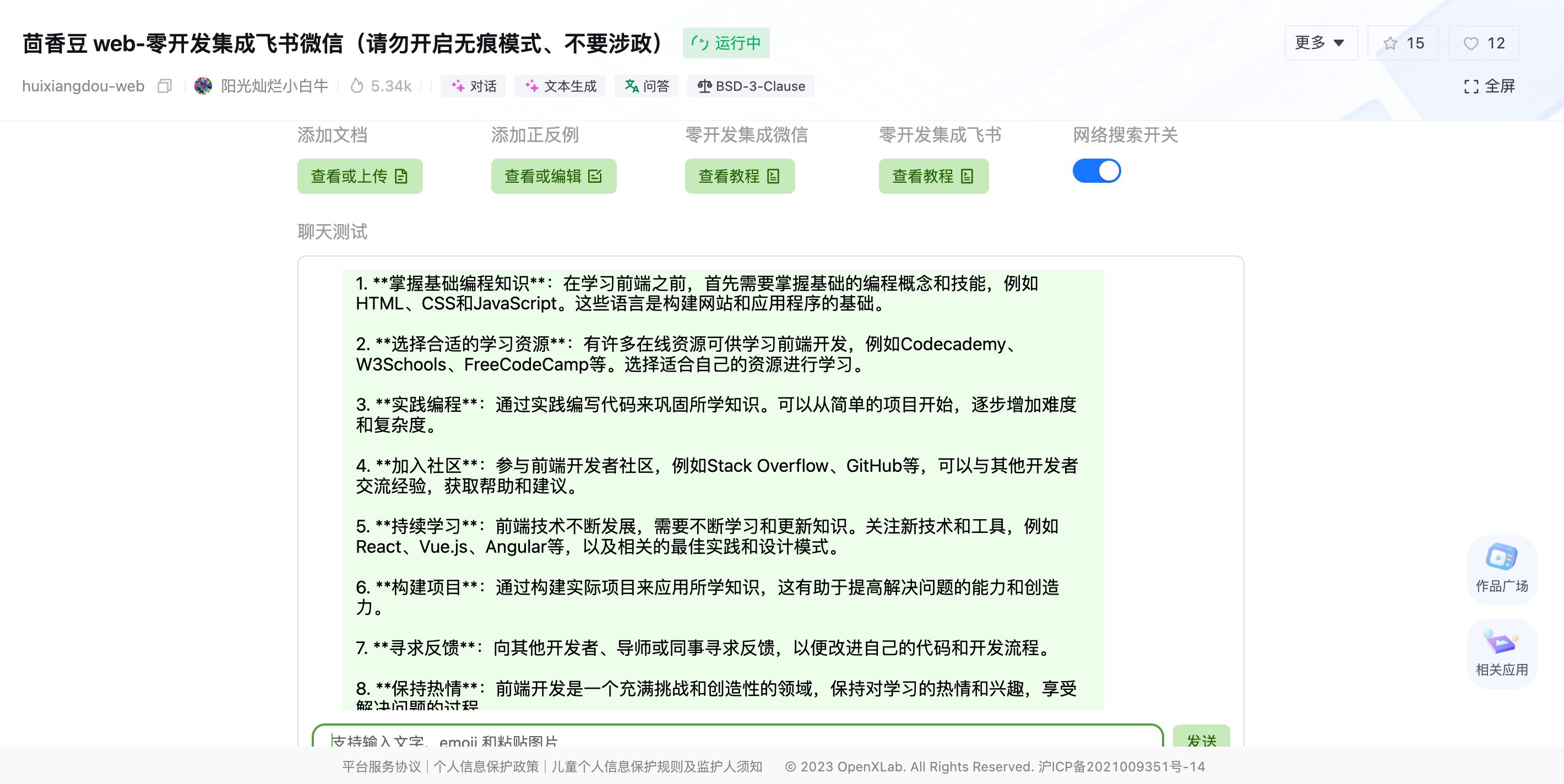
在茴香豆 Web 版中创建自己领域的知识问答助手
Gradio
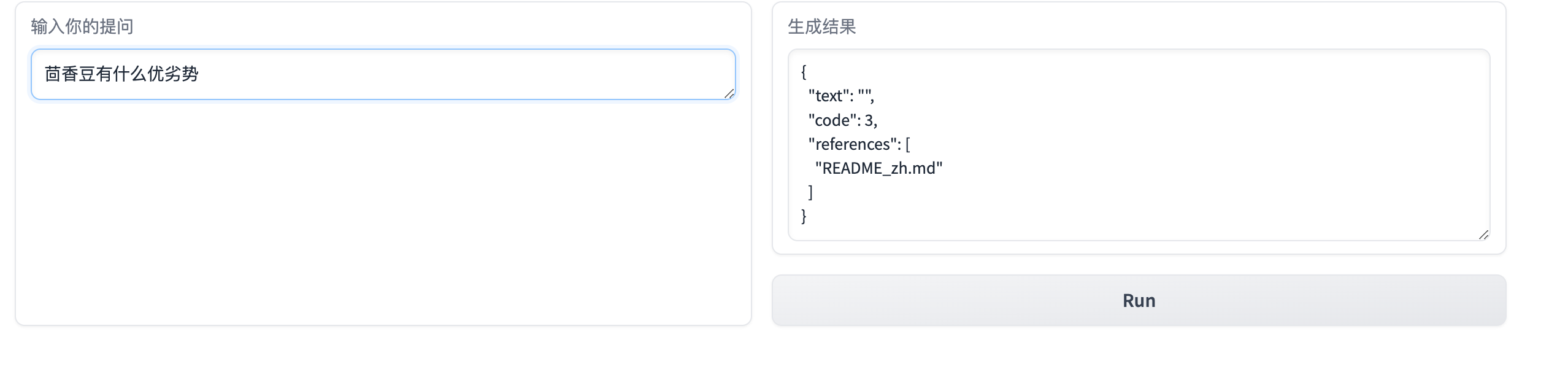
这个对问题太严格匹配了,需要调一下