V8
函数即对象
函数除了可以拥有常用类型的属性值之外,还拥有两个隐藏属性,分别是 name 属性和 code 属性。隐藏 name 属性的值就是函数名称,如果某个函数没有设置函数名,该函数对象的默认的 name 属性值就是 anonymous。
函数是一等公民
因为函数是一种特殊的对象,所以在 JavaScript 中,函数可以赋值给一个变量,也可以作为函数的参数,还可以作为函数的返回值。如果某个编程语言的函数,可以和这个语言的数据类型做一样的事情,我们就把这个语言中的函数称为一等公民。
对象的属性
排序属性和常规属性
我们把对象中的数字属性称为排序属性,在 V8 中被称为 elements,字符串属性就被称为常规属性,在 V8 中被称为 properties
数字属性按照索引值大小升序排列,字符串属性根据创建时的顺序升序排列。
快属性和慢属性
将不同的属性分别保存到 elements 属性和 properties 属性中,无疑简化了程序的复杂度,但是在查找元素时,却多了一步操作,基于这个原因,V8 采取了一个权衡的策略以加快查找属性的效率,这个策略是将部分常规属性直接存储到对象本身,我们把这称为对象内属性 (in-object properties)。
通常,我们将保存在线性数据结构中的属性称之为“快属性”,因为线性数据结构中只需要通过索引即可以访问到属性,虽然访问线性结构的速度快,但是如果从线性结构中添加或者删除大量的属性时,则执行效率会非常低,这主要因为会产生大量时间和内存开销。不过对象内属性的数量是固定的,默认是 10 个,
如果一个对象的属性过多时,V8 就会采取另外一种存储策略,那就是“慢属性”策略,但慢属性的对象内部会有独立的非线性数据结构 (词典) 作为属性存储容器。所有的属性元信息不再是线性存储的,而是直接保存在属性字典中。
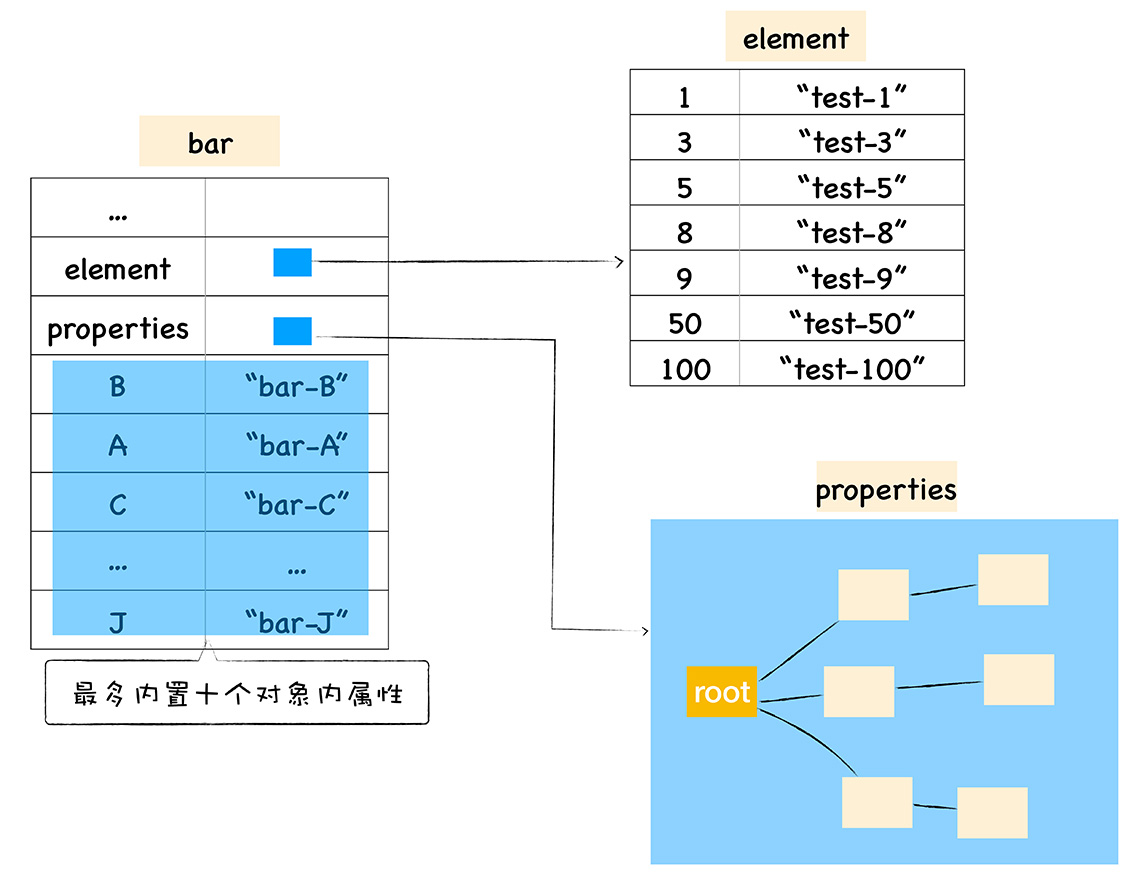
内存查看
function Foo(property_num, element_num) {
//添加可索引属性
for (let i = 0; i < element_num; i++) {
this[i] = `element${i}`;
}
//添加常规属性
for (let i = 0; i < property_num; i++) {
let ppt = `property${i}`;
this[ppt] = ppt;
}
}
var bar = new Foo(10, 10);Chrome 开发者工具切换到 Memory 标签,然后点击左侧的小圆圈就可以捕获当前的内存快照,查看创建不同数量属性的内存存储区别
// todo:和老师讲的有点不一样
V8 是怎么实现数组的
数组是什么? 数组的两个关键字是相同类型、连续内存 !
所以 Js 的数组根本不算一个真数组,那么他是怎么实现的呢
没错就是 对象,
快数组
慢数组
原型链和作用域链
作用域链是沿着函数的作用域一级一级来查找变量的,而原型链是沿着对象的原型一级一级来查找属性的
解析阶段
V8 会先编译顶层代码,在编译过程中会将顶层定义的变量和声明的函数都添加到全局作用域中,
全局作用域创建完毕后
进入执行阶段
变量:对全局作用域的值进行赋值,
函数的时候,同样需要经历两个阶段:编译和执行。在编译阶段,V8 会为 bar 函数创建函数作用域,执行阶段简单的执行 code
因为词法作用域是根据函数在代码中的位置来确定的,作用域是在声明函数时就确定好的了,所以我们也将词法作用域称为静态作用域。
和静态作用域相对的是动态作用域,动态作用域并不关心函数和作用域是如何声明以及在何处声明的,只关心它们从何处调用。换句话说,作用域链是基于调用栈的,而不是基于函数定义的位置的。
闭包
在 JavaScript 中,根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。比如外部函数是 foo,那么这些变量的集合就称为 foo 函数的闭包。
如何回收
通常,如果引用闭包的函数是一个全局变量,那么闭包会一直存在直到页面关闭;但如果这个闭包以后不再使用的话,就会造成内存泄漏。
如果引用闭包的函数是个局部变量,等函数销毁后,在下次 JavaScript 引擎执行垃圾回收时,判断闭包这块内容如果已经不再被使用了,那么 JavaScript 引擎的垃圾回收器就会回收这块内存。
类型系统
V8 是怎么执行加法操作的?
编译器和解释器
编译型语言在程序执行之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件,这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了。比如 C/C++、GO 等都是编译型语言。
而由解释型语言编写的程序,在每次运行时都需要通过解释器对程序进行动态解释和执行。比如 Python、JavaScript 等都属于解释型语言。

V8 执行 JavaScript 代码
总结
- 预编译阶段 变量提升 并且赋值 undefined
- 编译阶段 生成两部分代码 执行上下文(Execution context)**和**可执行代码。
- 执行阶段
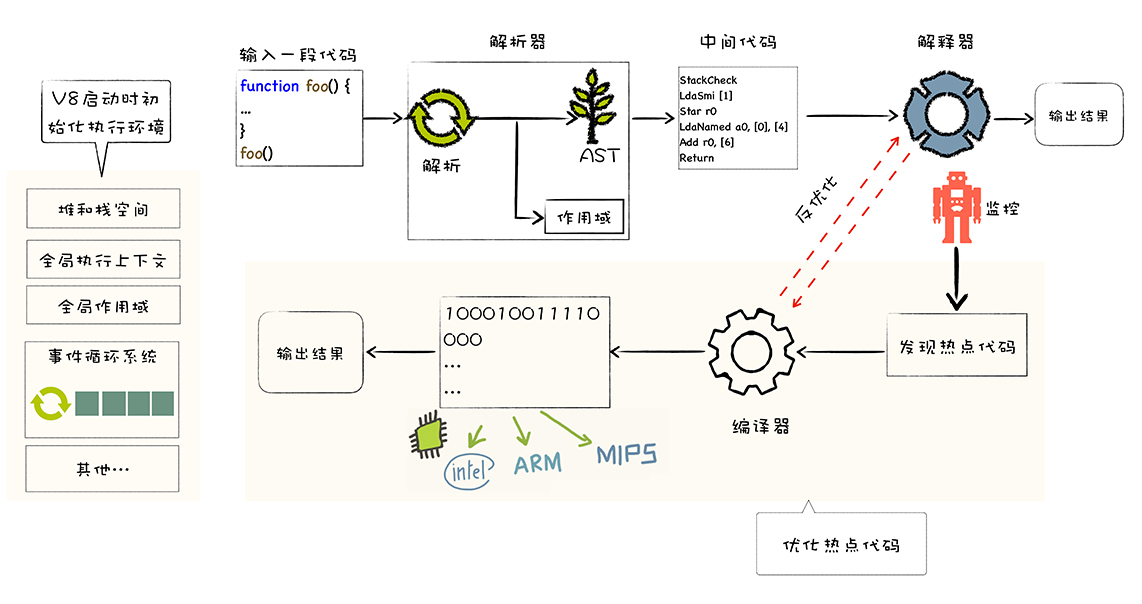
其实在执行 JavaScript 代码之前,V8 就已经准备好了代码的运行时环境,这个环境包括了堆空间和栈空间、全局执行上下文、全局作用域、内置的内建函数、宿主环境提供的扩展函数和对象,还有消息循环系统。
生成抽象语法树(AST)和执行上下文
将源代码转换为抽象语法树,并生成执行上下文。 AST 看成代码的结构化的表示,编译器或者解释器后续的工作都需要依赖于 AST,而不是源代码。AST 应用中最著名的一个项目是 Babel。Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码。
- 分词(tokenize),又称为词法分析,其作用是将一行行的源码拆解成一个个 token。
var myName = "xiaopang";
// token : var 、 myName 、= 、 'xiaopang'- 解析(parse),又称为语法分析,其作用是将上一步生成的 token 数据,根据语法规则转为 AST。
生成字节码

由于执行机器码的效率是非常高效的,所以早期 chorme 直接将 AST 转化成机器码进行保存。
但机器码占用内存过大,为了解决内存占用问题,V8 团队大幅重构了引擎架构,引入字节码。
字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行。
执行代码
通常,如果有一段第一次执行的字节码,解释器 Ignition 会逐条解释执行。在执行字节码的过程中,如果发现有热点代码(HotSpot),比如一段代码被重复执行多次,这种就称为热点代码,那么后台的编译器 TurboFan 就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率。我们把这种技术称之为即时编译(JIT)
微任务
MutationObserver 和 IntersectionObserver 两个性质应该差不多。我这里简称 ob。ob 是一个微任务,通过浏览器的 requestIdleCallback,在浏览器每一帧的空闲时间执行 ob 监听的回调,该监听是不影响主线程的,但是回调会阻塞主线程。当然有一个限制,如果 100ms 内主线程一直处于未空闲状态,那会强制触发 ob。
协程
协程是一种比线程更加轻量级的存在。你可以把协程看成是跑在线程上的任务,一个线程上可以存在多个协程,但是在线程上同时只能执行一个协程。最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
Async 和 await 的优化
V8 垃圾回收
GC
GC的发展和细节