RAG
RAG(Retrieval Augmented Generation)技术,通过检索与用户输入相关的信息片段,并结合外部知识库来生成更准确、更丰富的回答。解决 LLMs 在处理知识密集型任务时可能遇到的挑战, 如幻觉、知识过时和缺乏透明、可追溯的推理过程等。提供更准确的回答、降低推理成本、实现外部记忆。

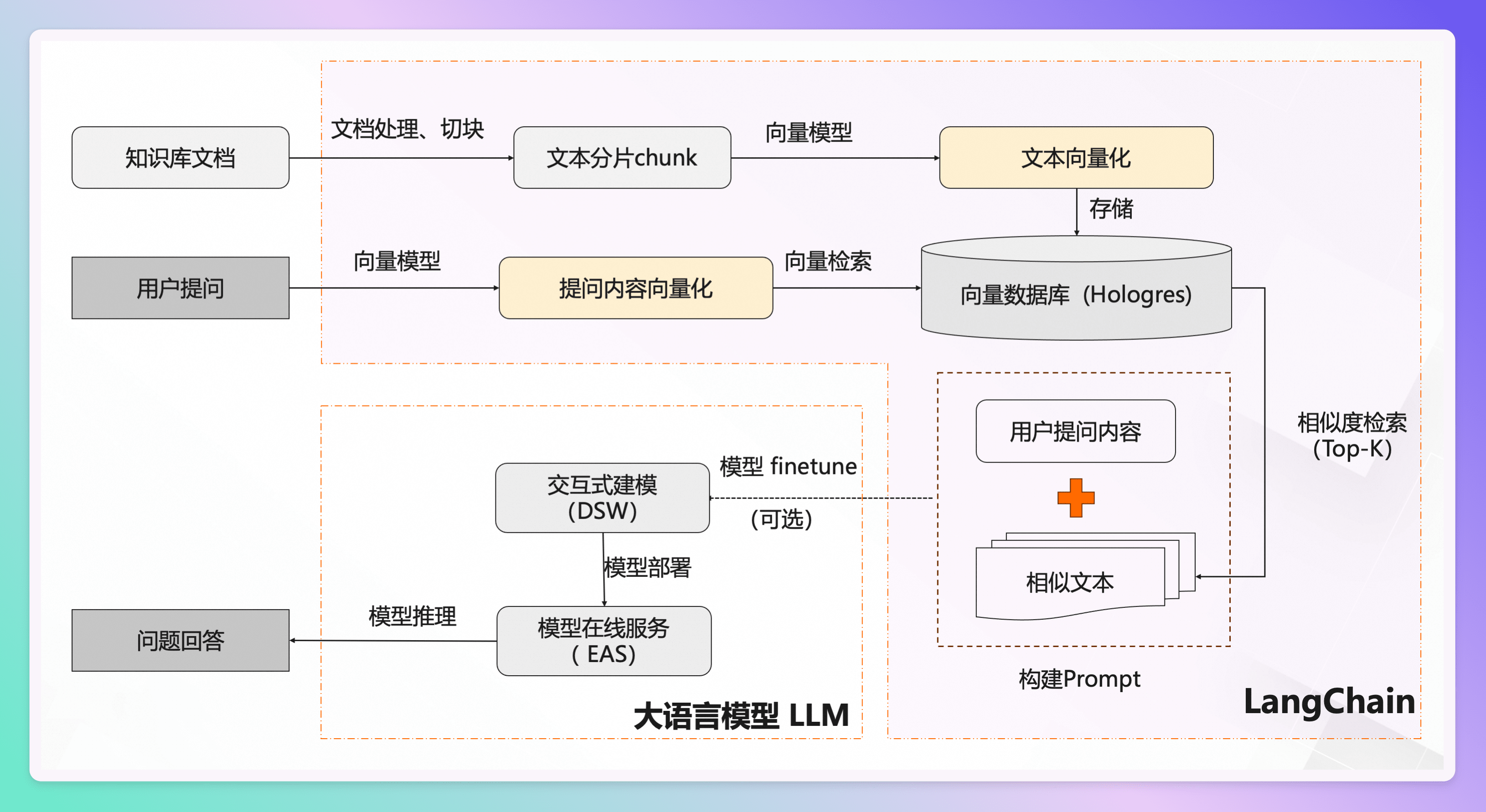
如上两张图所表现的整个过程,以及最终实现的功效,就称之为 rag。
简单来说的步骤就是
- 先将知识库的内容进行切割,切割的大小将影响最终的效果
- 把切分后的内容存入向量化数据库
- 用户提问之后,先将问题在向量库中进行相似性检索,找出匹配度高的答案。
- 然后把查询出来的结果,包装好 Prompt。
- 最后调用大语言模型,让大语言模型基于上一步的结果进行分析并形成最终的答案,返回给用户。
Langchain 则是针对如上步骤提供了整套封装的一个框架
RAG 能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。
方案扩展
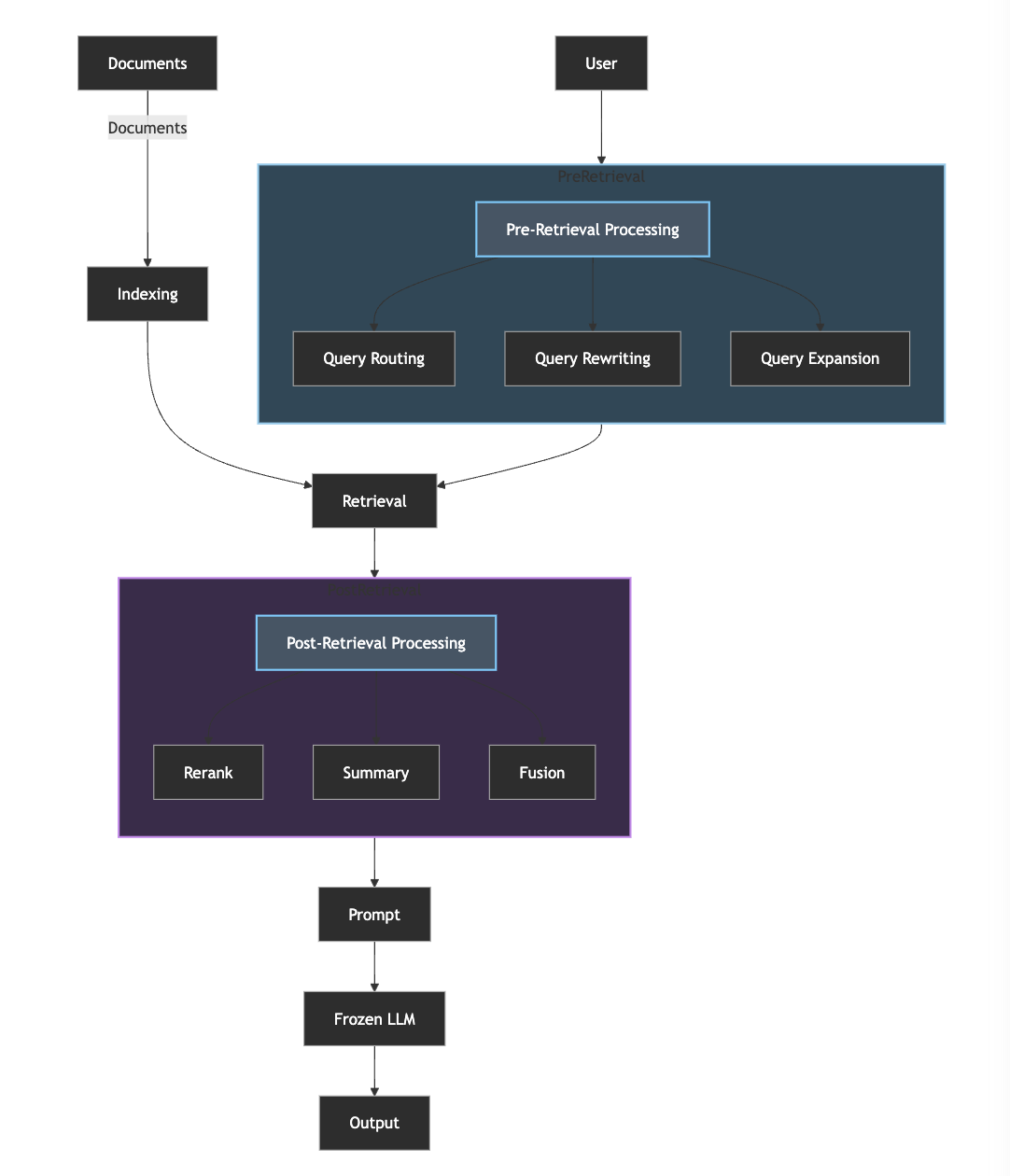
关键优化点:
- 检索前优化:
- Query Routing(路由):根据用户需求选择合适的检索方式
- Query Rewriting(重写):根据用户需求重写查询语句
- Query Expansion(扩展):根据用户需求扩展查询语句
- 检索后优化:
- Reranking(重排序):根据用户需求重排序检索结果
- Summary(总结):根据用户需求总结检索结果
- Fusion(融合):根据用户需求融合检索结果
具体实现
模块化 RAG 将系统拆分为独立可替换的功能模块:
「CRAG(Corrective Retrieval Augmented Generation)」

CRAG 的关键优化点:
- 「评估器模块(Evaluator)」:
- 对检索结果进行质量评估
- 将知识分类为:相关知识、存疑知识、不相关知识
- 通过评估确保输入到大模型的知识质量
- 减少”幻觉”的产生,提高答案准确性
- 作为知识分流的决策点,确定后续处理路径
- 「问题重写模块(Query Rewriter)」:
- 针对存疑/不相关知识进行问题重写
- 优化查询表达,提高检索准确度
- 通过重写扩展问题维度,获取更多相关上下文
- 实现查询的自我纠正和优化
- 作为知识补充的入口,提供二次检索机会
- 「重检索模块(Re-Searcher)」:
- 执行重写后问题的二次检索
- 补充和扩展知识库的查询范围
- 提供多轮检索的可能性
- 与原始检索形成互补,提高召回率
- 作为知识获取的最后一环,确保答案的完整性
这种模块化设计的优势:
- 各模块职责明确,可独立优化和替换
- 形成完整的知识评估-重写-检索闭环
- 通过多重保障机制提高最终答案质量
- 灵活应对不同质量的检索结果
- 支持系统的持续优化和迭代
RAG 的问题
当你按照开源社区一些框架给的教程,做出了一个 rag 的 demo 之后,你会发现,所呈现的效果,可能只有真正理想的效果 50% 都不到。
因为上面每个步骤的细节都需要你重复的开发调试,测试验证,每一个都是一个专业领域的课题。
比如说:
- 如何处理原始数据?涉及到数据来源,数据格式,数据类型,乃至内容类型混合 (比如一个 pdf 既有内容,又有表格,又有图片) 等
- 如何合理地切分 Chunk? 正如上文所言,不同大小的块儿最终会影响到检索到的结果
- 如何解决数据陈旧,并支持数据实时更新的能力?
- 如何选择 Embedding 模型?
- 大语言模型本地化的部署及维护
- 向量数据检索召回的设计
如何评估一个 RAG
RAG 流程中包含三大组件:
- 数据索引组件:数据向量和索引创建的工作
- 检索器组件:为 LLM 检索额外的上下文信息,以回答查询。
- 生成器组件:基于检索到的信息增强的提示生成答案。
开源项目
- dify: 一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流程、RAG 管道、代理功能、模型管理、可观察性功能等,让您可以快速从原型到生产。 Dify
- FastGPT:一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
- anything-llm:一个全栈应用程序,使您能够将任何文档、资源或内容片段转换为任何法学硕士可以在聊天期间用作参考的上下文。该应用程序允许您选择要使用的法学硕士或矢量数据库,并支持多用户管理和权限。
- ragflow:一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
- MaxKB: 基于 LLM 大语言模型的知识库问答系统。开箱即用,支持快速嵌入到第三方业务系统。
- QAnything: 是致力于支持任意格式文件或数据库的本地知识库问答系统,可断网安装使用。您的任何格式的本地文件都可以往里扔,即可获得准确、快速、靠谱的问答体验。目前已支持格式: PDF (pdf),Word (docx),PPT (pptx),XLS (xlsx),Markdown (md),电子邮件 (eml),TXT (txt),图片 (jpg,jpeg,png),CSV (csv),网页链接 (html)
- 包括我最近在学习的浦语第三课:茴香豆-搭建你的 RAG 智能助理
RAG和长上下文哪个好
- LaRA: RAG 与长上下文 LLM 到底哪个更好 | BestBlogs.dev
为了系统地比较RAG和LC LLM的性能,研究者设计并构建了LaRA benchmark。LaRA的开发过程分为四个关键阶段:长文本收集、任务设计、数据标注和评估方法制定。
几个结论:
- 上下文长度影响 随着上下文长度增加,RAG的优势变得更加明显。在32k上下文长度条件下,长上下文方法在所有模型中平均准确率比RAG高2.4%。然而,当上下文长度增至128k时,这一趋势发生逆转,RAG的平均表现超过长上下文方法3.68%。
- 任务类型表现差异 RAG在单点定位任务中与长上下文方法表现相当,并在幻觉检测方面展现出显著优势。相比之下,长上下文方法在推理任务和比较任务中表现更为出色,但是更容易产生幻觉。