HTTP 灵魂之问
把 HTTPS,HTTP 缓存,以及 HTTP 发展历史抽出来,剩余的将会用灵魂之问的方式复习和深入。
TCP/IP 网络分层模型是怎样分层的?
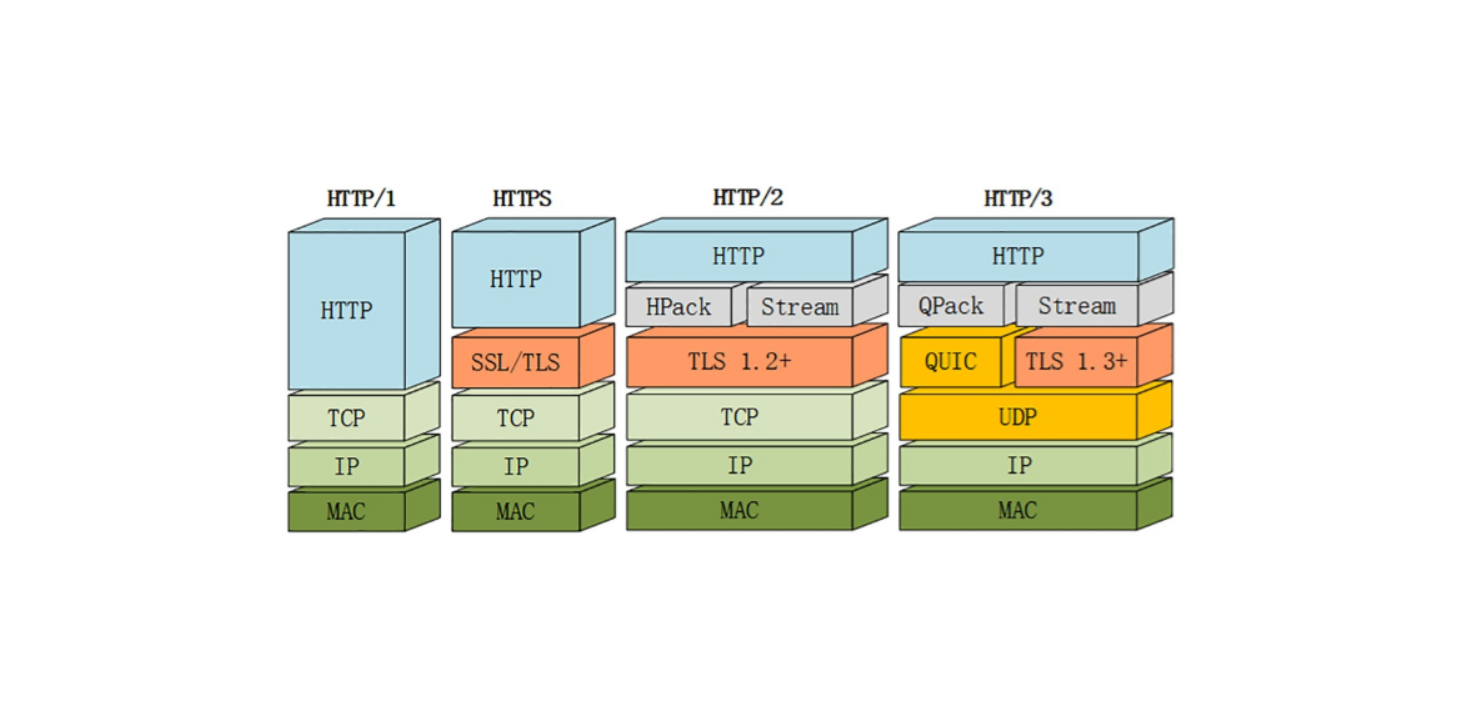
TCP/IP 四层网络分层,自下往上分别是链路层,网络互联层,传输层,应用层
另外值得一提的是,七层网络分层,物理层,数据链路层,网络互联层,传输层,会话层,表示层和应用层
IP 在网络互联层
TCP 在传输层,另一个比较有名的是 UDP
HTTP 协议就是应用层的一个协议,其他常见的还有 FTP,SMTP 等等
TCP 的三次握手和四次挥手简单说一下
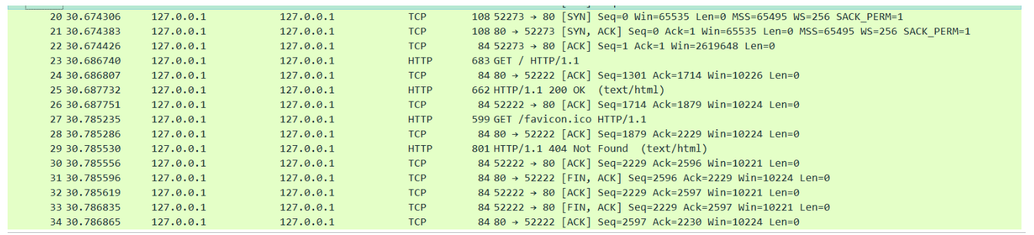
这是一次请求的抓包信息,可以清晰的看出流程
三次握手流程: Client → SYN → Server Server → SYN/ACK → Client Client → ACK → Server 后确认建立连接 数据传输完毕开始
4 次挥手:
Client → FIN → Server Server → ACK → Client Server → FIN → Client Client → ACK → Server → CLOSED Client → 2MSL 的时间 → CLOSED 关闭连接
为什么连接的时候是三次握手,关闭的时候却是四次握手?
因为当 Server 端收到 Client 端的 SYN 连接请求报文后,可以直接发送 SYN+ACK 报文。其中 ACK 报文是用来应答的,SYN 报文是用来同步的。
但是关闭连接时,当 Server 端收到 FIN 报文时,很可能并不会立即关闭 SOCKET,所以只能先回复一个 ACK 报文,告诉 Client 端,“你发的 FIN 报文我收到了”。只有等到我 Server 端所有的报文都发送完了,我才能发送 FIN 报文,因此不能一起发送。故需要四步握手。
为什么 TIME_WAIT 状态需要经过 2MSL(最大报文段生存时间)才能返回到 CLOSE 状态?
虽然按道理,四个报文都发送完毕,我们可以直接进入 CLOSE 状态了,但是我们必须假象网络是不可靠的,有可以最后一个 ACK 丢失。所以 TIME_WAIT 状态就是用来重发可能丢失的 ACK 报文。在 Client 发送出最后的 ACK 回复,但该 ACK 可能丢失。Server 如果没有收到 ACK,将不断重复发送 FIN 片段。所以 Client 不能立即关闭,它必须确认 Server 接收到了该 ACK。Client 会在发送出 ACK 之后进入到 TIME_WAIT 状态。Client 会设置一个计时器,等待 2MSL 的时间。如果在该时间内再次收到 FIN,那么 Client 会重发 ACK 并再次等待 2MSL。所谓的 2MSL 是两倍的 MSL(Maximum Segment Lifetime)。MSL 指一个片段在网络中最大的存活时间,2MSL 就是一个发送和一个回复所需的最大时间。如果直到 2MSL,Client 都没有再次收到 FIN,那么 Client 推断 ACK 已经被成功接收,则结束 TCP 连接。
为什么不能用两次握手进行连接?
三次握手是为什么确认两方都已经做好发送数据的准备,并开始协商初始序列号。如果只有两次握手,可能会导致死锁的发生
什么是 HTTP 协议?
HTTP 中文名 超文本传输协议,HTTP 是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范。是一个建立在 TCP/IP 之上的协议。
HTTP 的特点?HTTP 有哪些缺点?
特点
灵活可扩展
报文里的各个组成部分都没有做严格的语法语义限制,可以由开发者任意定制。 传输形式多样,不仅仅可以传输文本,还能传输图片、视频等任意数据,非常方便。
可靠传输
TCP 本身是一个“可靠”的传输协议,所以 HTTP 自 然也就继承了这个特性,能够在请求方和应答方之间“可靠”地传输数据。
无状态
服务器和客户端建立在互不知情的情况,没有上下文
请求-应答
采用的是一收一发的应答模式,
缺点:
明文
给了你可读性同时也给你黑客施展的空间
不安全
缺乏’身份验证’和’完整性验证’,所以之后出现了 HTTPS
性能
“请求-应答”模式则加剧了 HTTP 的性能问题,这就是著名的“队头阻塞”, 当顺序发送的请求序列中的一个请求因为某种原因被阻塞时,在后面排队的所有请求也一并被阻塞,会导致客户端迟迟收不到数据。
HTTP 如何处理大文件的传输?
数据压缩
客户端带着Accept-Encoding 头字段,里面是浏览器支持的压缩格式列表,例如 gzip、deflate、br 等
但是 gzip 等压缩算法通常只对文本文件有较好的压缩率,而图片、音频视频等多媒体数据本身就已经是高度压缩的。
分块传输
当响应头里出现 “Transfer-Encoding: chunked”时,就是告诉你这不是一个完整的文件,分成了很多块(和 content-length 相斥)
范围请求
相当于客户端的‘化整为零’ ,需要服务端在响应头放入 ‘Accept-Ranges: bytes ’ 请求头Range是 HTTP 范围请求的专用字段,格式是“**bytes=x-y **”,其中的 x 和 y 是以字节为单位的数据范围(偏移量)。
GET 和 POST 有什么区别?
- 从语义的角度,GET 去取数据,POST 是操作数据 从缓存的角度,GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。
- 从编码的角度,GET 只能进行 URL 编码,只能接收 ASCII字符,而 POST 没有限制。
- 从参数的角度,GET 一般放在 URL 中,因此不安全,POST 放在请求体中,更适合传输敏感信息。
- 从幂等性的角度,GET 是幂等的,而 POST 不是。(幂等表示执行相同的操作,结果也是相同的) 从TCP的角度,GET 请求会把请求报文一次性发出去,而 POST 会分为两个 TCP 数据包,首先发 header 部分,如果服务器响应 100(continue), 然后发 body 部分。(火狐浏览器除外,它的 POST 请求只发一个 TCP 包)
说一说你对 CDN 的理解?
CDN(Content Delivery Network)就是内容分发网络。
概念
在我们传输过程中是无法突破光速和距离等限制的,而 CDN 就是为了解决这个问题而诞生的。CDN 投⼊了大笔资金,在全国、乃⾄全球的各个大枢纽城市都建立了机房,部署了大量拥有⾼存储⾼带宽的节点,构建了⼀个专用网络。 CDN 各站点作为源站的‘缓存代理’,对内容进行分发,采取了‘就近原则’,省去了长途跋涉时间,实现网络加速。
DNS 负载均衡
主要的依据有这么⼏个:
- 看用户的 IP 地址,查表得知地理位置,找相对最近的边缘节点;
- 看用户所在的运营商网络,找相同网络的边缘节点;
- 检查边缘节点的负载情况,找负载较轻的节点;
- 其他,比如节点的“健康状况”、服务能⼒、带宽、响应时间等
CDN 的缓存代理
这里就有两个 CDN 的关键概念:“命中”和“回源”。 “命中”就是指用户访问的资源恰好在缓存系统里,可以直接返回给用户; “回源”则正相反,缓存里没有,必须用代理的方式回源站取。