反爬虫实战:从被封锁到自由爬取的完整路径
用 CloakBrowser 构建现代隐身爬虫
你写了一个爬虫,跑了不到 10 次就被封 IP。换了代理池,又被 Cloudflare 拦住。降速、加随机延时、换 User-Agent——全试了,还是过不了。
这不是你的代码问题。是浏览器本身在”出卖”你。
navigator.webdriver 暴露了自动化身份,Canvas 指纹泄露了渲染引擎特征,TLS 握手出卖了你的网络栈。现代反爬系统不看你请求了什么,它看你是谁。
读完这篇教程,你将理解现代反爬虫系统的工作原理,学会使用 CloakBrowser 构建稳定绕过反爬检测的自动化爬虫方案,并能将其集成到 Crawl4AI、browser-use、LangChain 等主流框架中。
第1章 你的爬虫为什么总被拦?
你有没有遇到过这种情况:用 requests 发一个 GET 请求,返回 403 Forbidden;换成 Playwright 打开页面,Cloudflare 的 Turnstile 验证转个不停;好不容易加了延时、换了 UA,数据量一上去 IP 又被封了。
大多数人以为换个代理就完事了。但代理只解决 IP 层面的问题。真正的封锁来自更深的地方。
1.1 一次典型的封锁经历
假设你要爬取一个受 Cloudflare 保护的电商网站。试试用最基础的方式:
import requests
response = requests.get(
"https://protected-shop.com/products",
headers={"User-Agent": "Mozilla/5.0 ..."}
)
print(response.status_code) # 403403。换 requests.Session(),加 Cookie,还是 403。因为 Cloudflare 根本不关心你的 Cookie——它在执行一段 JavaScript 来检测你是不是真实浏览器。requests 不会执行 JS,直接出局。
换成 Playwright:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto("https://protected-shop.com/products")
print(page.title()) # "Just a moment..." — Cloudflare 拦截页页面卡在 Cloudflare 的验证页。Playwright 确实能执行 JS,但反爬系统检测到了自动化痕迹:navigator.webdriver 返回 true,浏览器标识里包含 HeadlessChrome,Canvas 渲染结果和正常浏览器不一致。
1.2 反爬虫的三道防线
现代网站的反爬体系通常分为三层,从外到内依次拦截:
第一道:IP 信誉与频率限制。 你的请求频率超过阈值,或者 IP 来自已知的数据中心段,直接被拦截。这一层用代理池可以缓解,但成本高、维护麻烦。
第二道:浏览器指纹检测。 网站通过 JavaScript 收集你的 Canvas 渲染结果、WebGL 参数、音频处理特征、安装的字体列表、屏幕分辨率等几十个属性,生成一个唯一的”浏览器指纹”。自动化浏览器和真实浏览器在这些属性上存在系统性差异。
第三道:行为分析与挑战验证。 即使指纹一致,你的行为模式也可能暴露你。鼠标移动是不是直线?键盘输入有没有节奏变化?页面停留时间是否合理?反爬系统会综合分析这些信号。
大多数人卡在第二道和第三道防线,而这两道防线靠换代理是解决不了的。
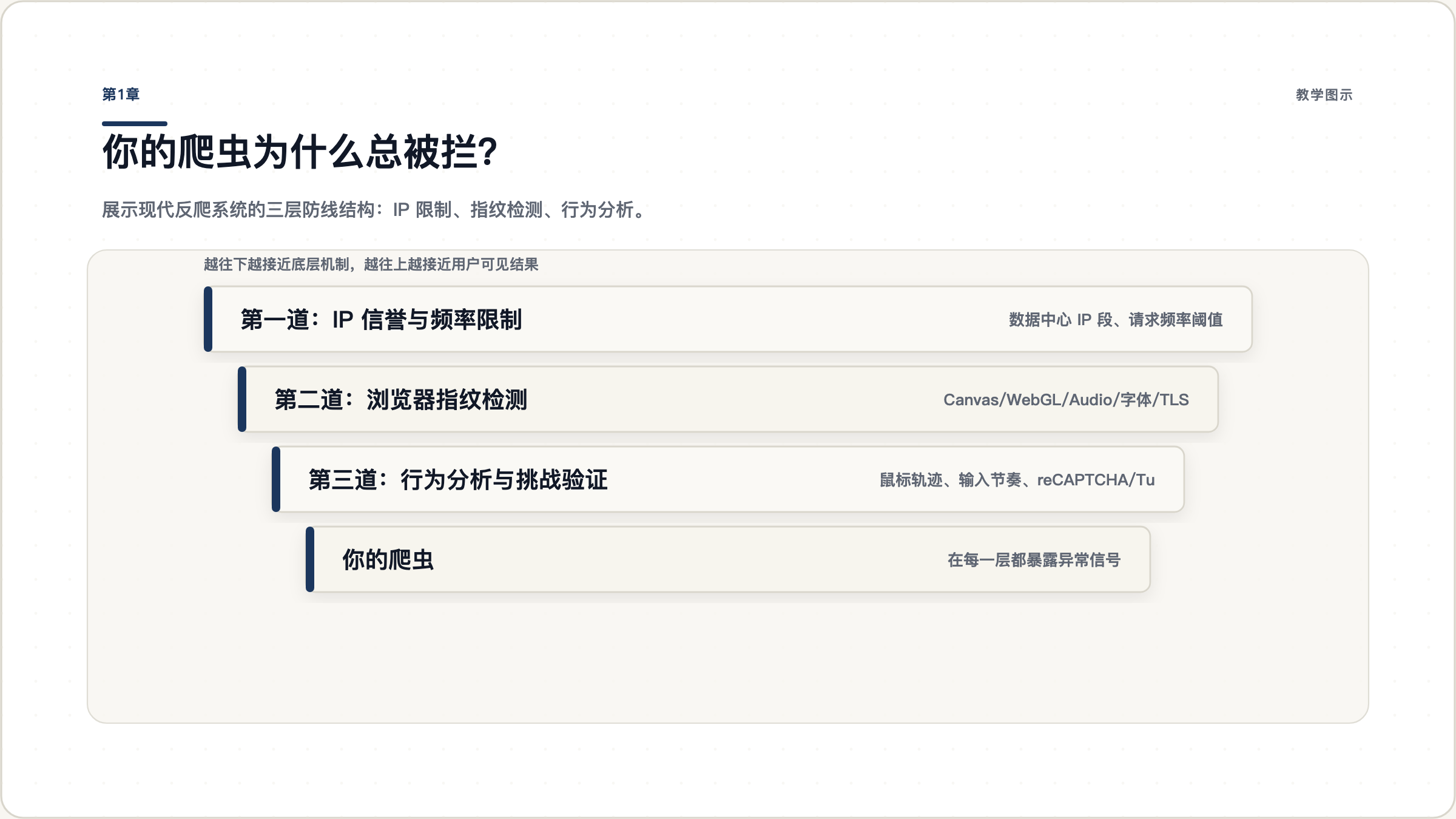
图 1.1: 现代反爬系统的三层防线。IP 限制只是最外层,指纹检测和行为分析才是真正的核心。
1.3 你的自动化浏览器”泄密”了什么
用 Playwright 或 Puppeteer 启动的浏览器,和正常用 Chrome 上网的用户,至少有以下区别:
| 泄密信号 | 真实浏览器 | 自动化浏览器 |
|---|---|---|
navigator.webdriver | false | true(Playwright/Puppeteer 默认) |
| User-Agent | 正常 Chrome UA | 包含 HeadlessChrome(headless 模式) |
window.chrome 对象 | 完整 | headless 模式下缺失或不完整 |
| CDP 协议端口 | 不开放 | 开放,可被检测 |
| Canvas 渲染结果 | 与硬件相关,自然差异 | 虚拟环境中系统性差异 |
| TLS 指纹(JA3) | 与 Chrome 版本一致 | 可能不一致 |
这意味着,即使你修改了 User-Agent、隐藏了 navigator.webdriver,反爬系统仍然可以通过其他几十个信号判断你在用自动化工具。
要注意
指纹检测不是检查某一个属性,而是综合所有属性的一致性。单独修改一两个属性反而会让你的指纹更加”异常”。
检查点: 打开浏览器开发者工具,在 Console 中输入 navigator.webdriver,看看返回什么。如果是 true,说明这个浏览器可以被识别为自动化工具。
第2章 反爬系统是怎么识别你的?
理解敌人才能打败敌人。这一章我们深入看看反爬系统到底在检测什么,以及为什么简单的伪装总是不够。
2.1 浏览器指纹:你的数字身份证
浏览器指纹是一组由你的浏览器和硬件环境共同决定的特征集合。即使你不登录、不提供任何个人信息,这些特征也能唯一标识你。
Canvas 指纹 是最常用的检测手段之一。网站会让浏览器在 Canvas 上绘制一段文字或图形,然后读取像素数据。不同的 GPU、驱动、操作系统会产生微妙但稳定的差异。自动化浏览器通常运行在虚拟显示环境中,Canvas 渲染结果和真实环境有系统性差异。
// 网站用于检测 Canvas 指纹的典型代码
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
ctx.textBaseline = 'top';
ctx.font = "14px 'Arial'";
ctx.fillText('Browser fingerprint test', 2, 2);
const fingerprint = canvas.toDataURL();
// 发送到服务器,与已知机器人指纹对比WebGL 指纹 检测你的 GPU 型号和渲染能力。网站通过 WEBGL_debug_renderer_info 扩展获取 GPU 供应商和型号。如果你的 User-Agent 声称是 macOS,但 GPU 却报告为 Linux 服务器的显卡,这就不一致了。
AudioContext 指纹 利用音频处理引擎的微小差异。不同浏览器和硬件对同一段音频的处理结果有极细微的差别,足以用来区分真实用户和自动化工具。
字体枚举 检查你系统上安装了哪些字体。Linux 服务器和 Windows/Mac 桌面系统的字体集差异很大,这是判断是否为服务器环境的重要信号。
2.2 网络层指纹:不只是 IP
反爬系统不只看你的 IP 地址,还看你建立连接的方式。
TLS/JA3 指纹 是一种基于 TLS 握手过程的识别技术。不同的客户端(Chrome、Firefox、Python requests、curl)在 TLS 握手时发送的参数组合不同,包括支持的加密套件、扩展、椭圆曲线等。这些参数组合形成一个唯一的”指纹”。
关键问题是:Python 的 requests 库和 httpx 使用的 TLS 指纹与 Chrome 完全不同。即使你完美伪装了 User-Agent,TLS 握手阶段就已经暴露了你的真实身份。
Chrome JA3: 769,47...(正常)
Python httpx: 771,4865...(异常,与 Chrome 不匹配)
HTTP/2 帧指纹 进一步提高了识别精度。不同的 HTTP/2 实现在 SETTINGS 帧、WINDOW_UPDATE、优先级设置等方面有差异,足以区分真实浏览器和自动化工具。
2.3 行为指纹:你怎么用浏览器
即使你的浏览器指纹和网络指纹都完美伪装,你的操作行为仍然可能暴露你。
鼠标轨迹 是最明显的信号。真实用户的鼠标移动遵循贝塞尔曲线,有加速和减速,会有随机的微小偏移。自动化脚本的鼠标通常是瞬间跳转到目标位置,或者走完美的直线。
键盘输入 的节奏也很关键。真人打字有快有慢,每个字符之间的间隔不完全均匀,偶尔还会打错再删除。自动化脚本要么一次输入整个字符串,要么以固定间隔逐字符输入。
滚动行为 同样有规律。真人滚动是加速-匀速-减速的过程,会停顿、回看、跳跃。自动化脚本要么不滚动,要么匀速滚动到底。
2.4 环境一致性检测
现代反爬系统最强大的武器是”一致性检查”。它不只看单一信号,而是检查所有信号是否构成一个合理的整体。
| 检查维度 | 一致性要求 | 常见失误 |
|---|---|---|
| User-Agent 与平台 | UA 声称 macOS,平台应返回 MacIntel | 脚本随意设 UA,与实际不匹配 |
| GPU 与操作系统 | macOS 应显示 Apple GPU | 服务器环境 GPU 信息与声称 OS 不符 |
| 时区与 IP 地理位置 | IP 在东京,时区应为 JST | 使用海外代理但时区还是本地 |
| 语言与地区 | 日本 IP 应有日语相关设置 | 语言和地区设置与 IP 位置不匹配 |
| 屏幕分辨率与设备类型 | 桌面 UA 应有桌面分辨率 | 移动端分辨率配桌面 UA |
如果这些信号之间存在矛盾,反爬系统会给你打上”可疑”标签,即使没有任何单一信号明确表明你是机器人。
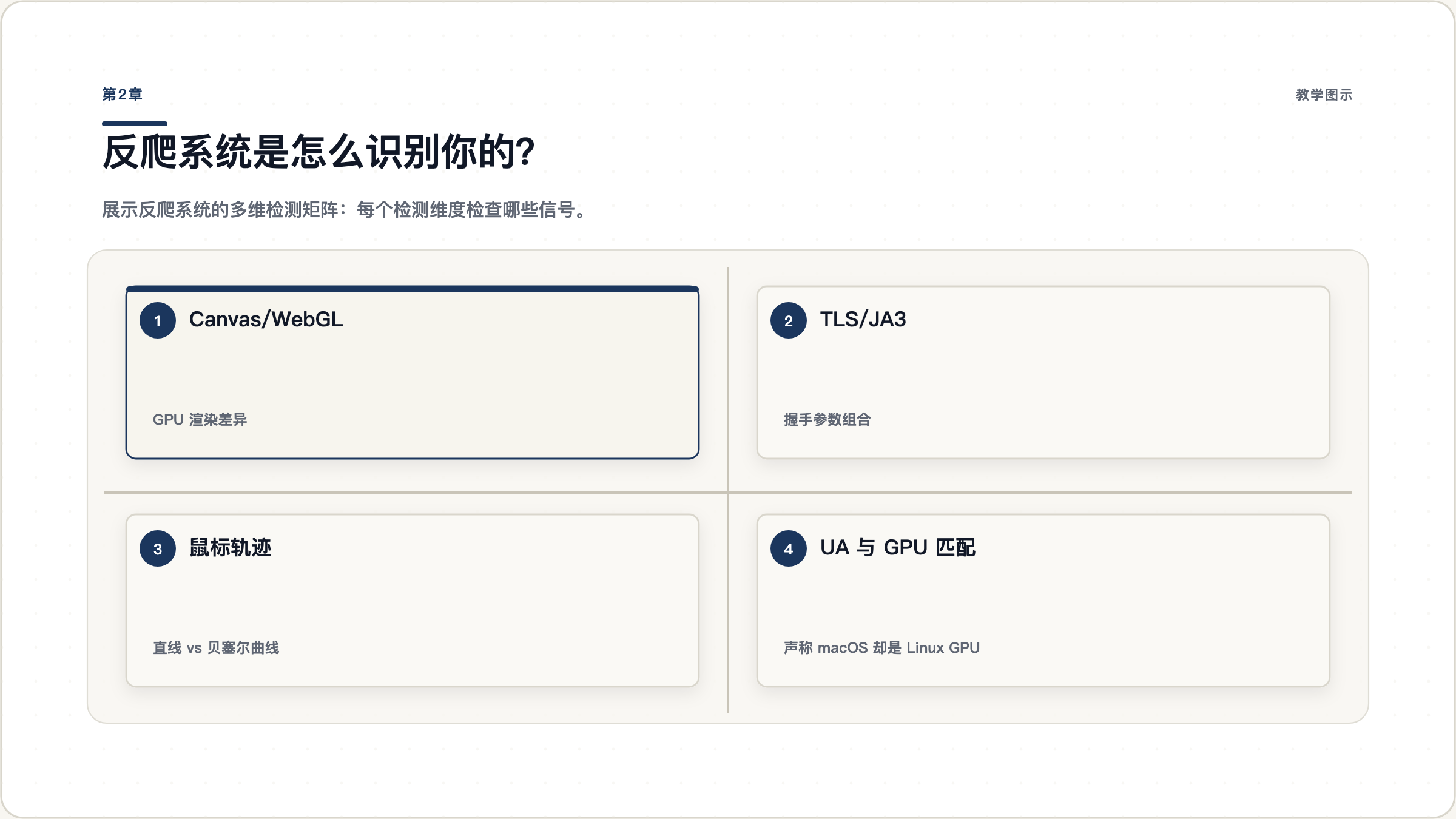
图 2.1: 反爬系统的多维检测矩阵。每一行是一个检测维度,每一列是一种信息来源。真正有效的反检测需要让所有维度保持一致。
检查点: 访问 BrowserScan 或 CreepJS,看看你的浏览器泄露了多少信息。记录哪些维度检测到了异常。
第3章 隐身浏览器的工作原理
知道了反爬系统检测什么,接下来的问题是:怎么让自动化浏览器在所有这些维度上都”看起来正常”?
答案取决于你从哪个层面去修改。
3.1 反检测的三种路线
目前主流的反检测方案有三种,从浅到深:
JS 注入方案(如 puppeteer-extra-plugin-stealth)在页面加载前注入 JavaScript,覆盖或修补会被检测到的属性。比如把 navigator.webdriver 改成 false,补全 window.chrome 对象,模拟 Chrome 的插件数组。
这种方式实现简单,但有根本性缺陷:注入行为本身可以被检测到。反爬系统可以检查属性是否被重新定义(Object.getOwnPropertyDescriptor),可以检测到 JS 补丁的执行痕迹。
配置修改方案(如 undetected-chromedriver)通过修改 ChromeDriver 的二进制文件、调整启动参数等方式来隐藏自动化特征。比 JS 注入深入一些,但仍然无法控制 TLS 指纹、Canvas 渲染等底层行为。
源码补丁方案(如 CloakBrowser)直接修改 Chromium 的 C++ 源代码,在编译阶段就把所有自动化痕迹抹掉。这是目前最深入、最有效的方案。
3.2 CloakBrowser 的源码级补丁
CloakBrowser 对 Chromium 应用了 48 到 57 个 C++ 源码级补丁(数量取决于平台和版本),覆盖了以下检测维度:
| 补丁类别 | 修改内容 | 解决的检测 |
|---|---|---|
| Canvas | 修改 Canvas 渲染的底层计算 | Canvas 指纹异常 |
| WebGL | 修改 GPU 信息返回逻辑 | WebGL 指纹与 OS 不匹配 |
| Audio | 调整 AudioContext 的处理精度 | 音频指纹检测 |
| Fonts | 修改字体枚举返回结果 | 字体集与 OS 不一致 |
| GPU/Screen | 使 GPU 和屏幕信息与声称的 OS 一致 | 环境一致性检测 |
| WebRTC | 修改 WebRTC 相关接口 | 本地 IP 泄露 |
| Navigator | 从编译层面让 navigator.webdriver 返回 false | WebDriver 检测 |
| Headless | 移除 HeadlessChrome 标识 | Headless 模式检测 |
| CDP | 隐藏 CDP 协议的存在 | 自动化协议检测 |
| Network | 调整网络栈参数使 TLS 指纹与 Chrome 一致 | JA3 指纹检测 |
| Storage | 修改存储配额相关值 | 存储特征检测 |
| Automation | 移除所有自动化相关的内部标记 | 综合自动化检测 |
这些补丁不是通过注入 JavaScript 或修改配置实现的,而是直接改了 Chromium 渲染引擎和浏览器内核的 C++ 代码。这意味着从任何角度去检测——JavaScript 层、网络层、系统调用层——都看不到”修改痕迹”,因为这些修改就是浏览器本身的一部分。
3.3 实测效果对比
CloakBrowser 的 README 提供了一组测试数据,展示了它和标准 Playwright 浏览器在主要检测服务上的对比:
| 检测服务 | 标准 Playwright | CloakBrowser |
|---|---|---|
| reCAPTCHA v3 分数 | 0.1(机器人) | 0.9(人类级别) |
| Cloudflare Turnstile | 拦截 | 通过 |
| FingerprintJS | 检测到自动化 | 未检测到 |
| BrowserScan | 异常 | 正常(4/4) |
navigator.webdriver | true | false |
| CDP 检测 | 被检测到 | 未检测到 |
| TLS 指纹 | 与 Chrome 不匹配 | 与 Chrome 一致 |
reCAPTCHA v3 的分数特别有说服力。0.1 是明确的机器人信号,0.9 已经接近正常用户的水平。这意味着即使 Google 的风控系统也认为这个浏览器是真人。
要注意
这些数据来自 CloakBrowser 的官方测试。实际效果会受到代理质量、目标网站策略、使用方式等因素影响。建议在实际项目中自行验证。
图 3.1: 三种反检测方案的覆盖范围对比。JS 注入只覆盖表层,配置修改覆盖中层,源码补丁从底层全面覆盖。覆盖范围越深,能绕过的检测越多。
检查点: 思考你当前项目中遇到的反爬封锁,主要是哪个层面的问题?是指纹检测、网络层检测,还是行为检测?
第4章 CloakBrowser 快速上手
理论讲够了,开始动手。这一章带你从安装到成功爬取一个受保护网站,全程不超过 10 分钟。
4.1 安装
Python 版本:
pip install cloakbrowser首次运行时,CloakBrowser 会自动下载经过补丁处理的 Chromium 二进制文件(约 150-200MB),并缓存到本地。后续运行直接使用缓存,无需重复下载。
Node.js 版本:
npm install cloakbrowser playwright-coreNode.js 版本支持 Playwright 和 Puppeteer 两种后端,默认使用 Playwright。
4.2 最简示例:5 行代码爬取受保护网站
CloakBrowser 的 API 和 Playwright 完全一致。如果你之前用过 Playwright,迁移只需要换一个 import:
from cloakbrowser import launch
browser = launch(headless=True)
page = browser.new_page()
page.goto("https://www.zhihu.com") # 知乎有 Cloudflare 保护
print(page.title())
browser.close()对比一下用普通 Playwright 的写法:
# 普通 Playwright — 会被检测
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
# ...
# CloakBrowser — 绕过检测
from cloakbrowser import launch
browser = launch(headless=True)
# 其余代码完全一样唯一的区别是第一行:把 Playwright 的 launch 换成 CloakBrowser 的 launch。整个 API 接口(new_page()、goto()、click()、type()、query_selector() 等)完全兼容。
4.3 Headless 与 Headed 模式
Headless 模式 (headless=True):不显示浏览器窗口,适合服务器部署。CloakBrowser 在 headless 模式下也能通过所有检测,因为它修改了 Chromium 内核对 headless 的内部标识。
Headed 模式 (headless=False):显示浏览器窗口,适合调试。你可以直观地看到浏览器的行为是否符合预期,检查是否触发了验证码等。
建议在开发阶段用 headed 模式调试,确认无误后切换到 headless 部署。
4.4 Node.js 版本基本用法
import { launch } from "cloakbrowser";
const browser = await launch({ headless: true });
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title());
await browser.close();Node.js 版本默认使用 Playwright 后端。如果想用 Puppeteer 后端:
import { launchPuppeteer } from "cloakbrowser/puppeteer";
const browser = await launchPuppeteer({ headless: true });
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title());
await browser.close();4.5 常见启动参数
from cloakbrowser import launch
browser = launch(
headless=True,
proxy="http://user:pass@proxy-server:8080", # 代理
viewport={"width": 1920, "height": 1080}, # 窗口大小
args=["--disable-blink-features=AutomationControlled"], # 额外参数
)CloakBrowser 会自动添加必要的隐身参数,你不需要手动配置那些复杂的 --disable-blink-features 之类的标志。大多数情况下,只需要指定 headless 和 proxy 即可。
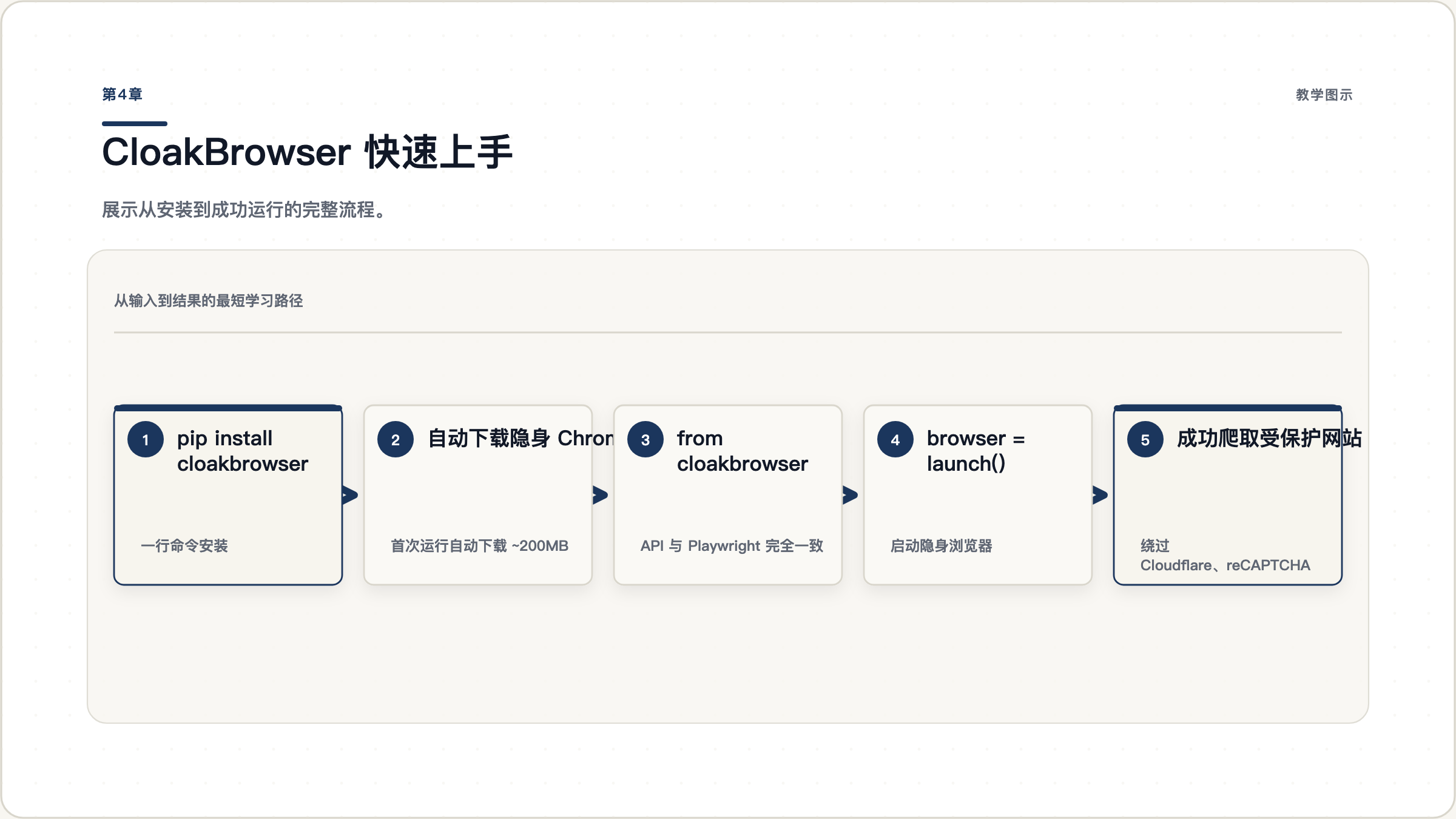
图 4.1: 从安装到成功运行的完整流程。安装只需要一行命令,代码和 Playwright 几乎一样。
练习: 安装 CloakBrowser,选择一个你知道有反爬保护的网站,尝试用 5 行代码爬取页面标题。对比普通 Playwright 和 CloakBrowser 的结果。
第5章 代理、GeoIP 与人类行为模拟
基础用法能让你通过大多数检测,但要构建稳定的生产级爬虫,还需要在代理、地理位置一致性和行为模拟上下功夫。
5.1 代理配置
CloakBrowser 支持三种代理协议:
from cloakbrowser import launch
# HTTP 代理
browser = launch(proxy="http://user:pass@proxy:8080")
# HTTPS 代理
browser = launch(proxy="https://user:pass@proxy:8080")
# SOCKS5 代理
browser = launch(proxy="socks5://user:pass@proxy:1080")住宅代理 和 数据中心代理 的选择取决于目标网站的反爬强度:
| 代理类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 数据中心代理 | 速度快、成本低 | IP 段容易被识别 | 反爬较弱的网站 |
| 住宅代理 | IP 看起来像普通用户 | 速度慢、成本高 | 反爬强的网站 |
| 静态住宅代理 | 固定 IP,可维持会话 | 成本最高 | 需要长期登录的场景 |
要注意
好的代理比好的工具更重要。即使用了 CloakBrowser,如果代理 IP 已经被标记为可疑,仍然可能被拦截。
5.2 GeoIP 自动匹配
这是一个容易被忽视但极其重要的细节:你的浏览器时区、语言设置必须和代理 IP 的地理位置一致。
举例:你用了一个日本东京的代理 IP,但浏览器时区还是 Asia/Shanghai(北京时间),语言还是 zh-CN。反爬系统一看就知道不对——一个在东京上网的用户,为什么系统设置是中文?
CloakBrowser 的 geoip=True 参数可以自动解决这个问题:
from cloakbrowser import launch
browser = launch(
proxy="socks5://user:pass@tokyo-proxy:1080",
geoip=True, # 自动从代理 IP 检测地理位置
)
# CloakBrowser 会自动设置:
# - timezone: Asia/Tokyo
# - locale: ja_JP
# - 语言相关 HTTP 头启用 GeoIP 后,CloakBrowser 会解析代理的出口 IP,查询其地理位置,然后自动设置对应的时区和语言环境。这确保了浏览器环境与 IP 位置的完全一致。
5.3 人类行为模拟层
CloakBrowser 内置了一套人类行为模拟系统,通过 humanize=True 开启:
from cloakbrowser import launch
browser = launch(humanize=True, human_preset="careful")
page = browser.new_page()
page.goto("https://example.com")
# 所有交互都会自动模拟人类行为
page.click("#submit-button") # 鼠标沿贝塞尔曲线移动到目标
page.type("#search", "CloakBrowser") # 逐字符输入,有随机间隔鼠标移动 使用贝塞尔曲线生成自然的移动轨迹,包含加速、减速和随机的微小偏移。如果目标元素不在视口内,会先滚动到可见位置,再移动鼠标。
键盘输入 模拟真人打字的节奏:每个字符之间有随机的间隔(80-200ms),偶尔会有”思考停顿”(200-500ms),甚至极小概率出现打字错误并立即纠正。
滚动行为 采用加速-匀速-减速的三阶段模型,中间可能穿插随机的短暂停顿和回看。
CloakBrowser 提供两种预设:
| 预设 | 特点 | 适用场景 |
|---|---|---|
default | 平衡速度和自然度 | 大多数场景 |
careful | 更慢更谨慎,更接近真人 | 高安全级别网站 |
5.4 持久化上下文
默认情况下,每次 launch() 都会创建一个全新的浏览器实例,相当于 incognito 模式。但 incognito 模式有一个问题:一些高级检测服务(如 BrowserScan)会给 incognito 模式扣分。
CloakBrowser 支持 launchPersistent() 来保持浏览器上下文:
from cloakbrowser import launch_persistent_context
context = launch_persistent_context(
user_data_dir="/path/to/profile",
headless=True,
)
page = context.new_page()
page.goto("https://example.com")
# cookies、localStorage、session 都会保留
# 下次启动时自动恢复持久化上下文的好处:
- 避免 incognito 检测:BrowserScan 等服务对 incognito 模式扣 10% 分
- 维持登录状态:跨会话保持 cookies,不需要反复登录
- 浏览器历史自然:有真实的浏览记录,不会像全新浏览器一样”干干净净”
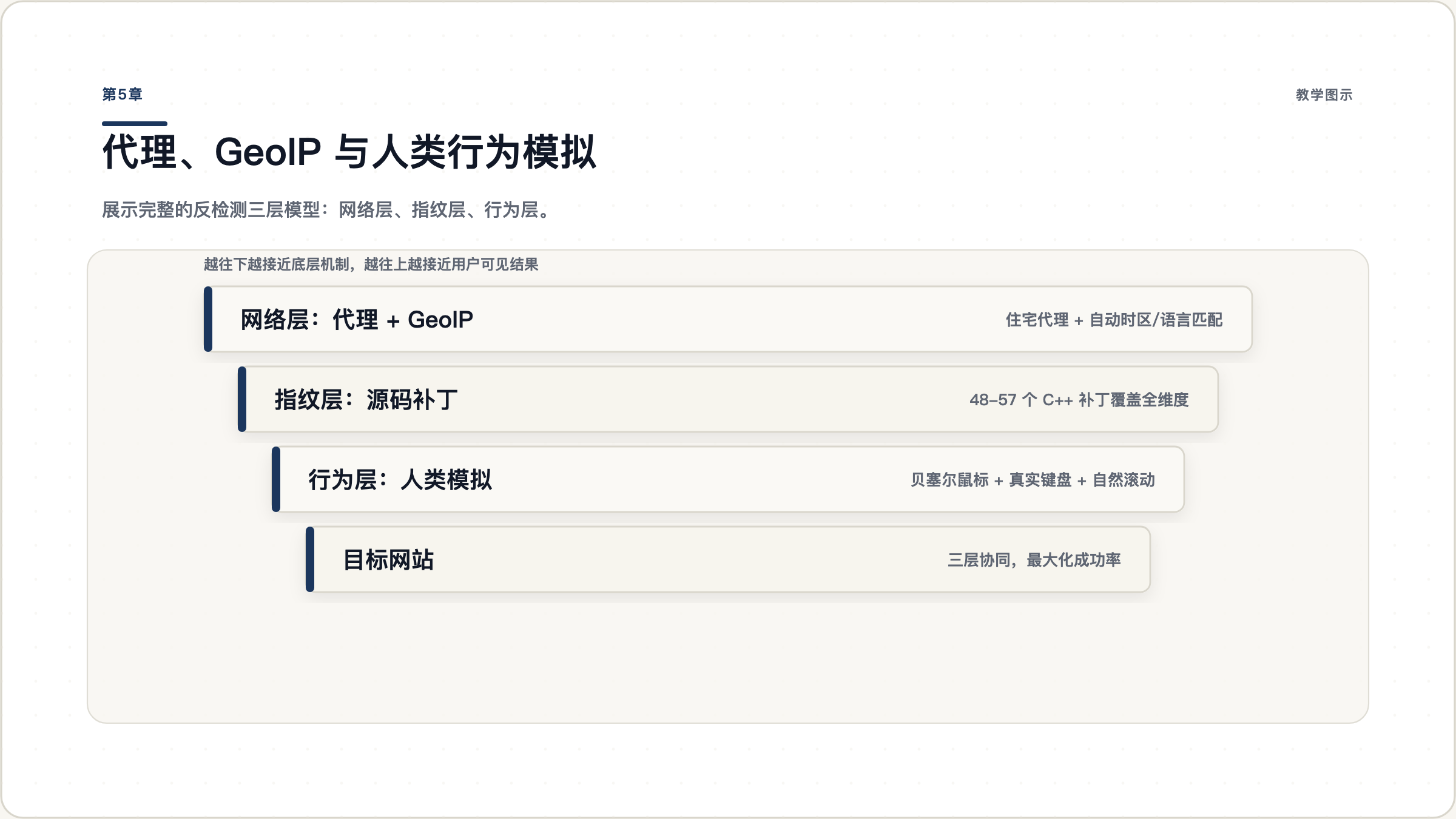
图 5.1: 完整的反检测三层模型。底层是代理+GeoIP 确保网络层一致,中层是源码补丁确保指纹一致,顶层是人类行为模拟确保行为一致。三层协同才能最大化成功率。
练习: 配置一个代理(即使是用免费代理测试),启用 geoip=True 和 humanize=True,完整运行一次爬取。对比有无这些配置时 BrowserScan 的评分差异。
第6章 与主流爬虫框架集成
CloakBrowser 不只是一个独立的爬虫工具,它可以作为底层隐身引擎,接入你已经熟悉的爬虫框架。核心模式是通过 CDP(Chrome DevTools Protocol)暴露调试端口,让外部框架连接。
6.1 与 Crawl4AI 集成
Crawl4AI 是一个专为 LLM 数据准备设计的智能爬虫框架。和 CloakBrowser 结合后,可以爬取受保护网站并直接输出 LLM 友好的 Markdown 内容。
import asyncio
from cloakbrowser import launch_async
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
async def main():
# 启动 CloakBrowser,暴露 CDP 端口
browser = await launch_async(
headless=True,
args=["--remote-debugging-port=9222", "--remote-debugging-address=127.0.0.1"],
)
# Crawl4AI 通过 CDP 连接
browser_config = BrowserConfig(
cdp_url="http://127.0.0.1:9222",
)
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://protected-site.com/article",
config=CrawlerRunConfig(),
)
print(result.markdown)
await browser.close()
asyncio.run(main())6.2 与 browser-use 集成
browser-use 让 AI Agent 通过自然语言指令控制浏览器。和 CloakBrowser 结合,AI Agent 可以在隐身浏览器中执行任务,不受反爬限制。
import asyncio
from cloakbrowser import launch_async
from browser_use import Agent, BrowserSession
async def main():
# 启动隐身浏览器
browser = await launch_async(
headless=True,
args=["--remote-debugging-port=9242"],
)
# browser-use 通过 CDP 连接
session = BrowserSession(cdp_url="http://127.0.0.1:9242")
agent = Agent(
task="搜索 CloakBrowser 的 GitHub 仓库,获取星标数",
browser_session=session,
)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())6.3 与 Scrapling 集成
Scrapling 是一个智能自适应的网页解析库,能自动适应网页结构变化。通过 CDP 连接 CloakBrowser 后,可以在隐身浏览器中使用 Scrapling 的全部能力。
import asyncio
from cloakbrowser import launch_async
from scrapling import Fetcher
async def main():
browser = await launch_async(
headless=True,
args=["--remote-debugging-port=9222"],
)
# Scrapling 通过 CDP URL 连接
fetcher = Fetcher(cdp_url="http://127.0.0.1:9222")
page = await fetcher.async_get("https://protected-site.com/products")
# 使用 Scrapling 的智能选择器
products = page.css(".product-card")
for product in products:
print(product.css_first("h3").text())
await browser.close()
asyncio.run(main())6.4 与 LangChain 集成
如果你在构建 RAG 应用,需要从网页采集数据作为知识库,CloakBrowser + LangChain 的组合可以让你稳定地采集受保护的网页内容。
from cloakbrowser import launch
from langchain_community.document_loaders import PlaywrightURLLoader
# 启动隐身浏览器
browser = launch(headless=True)
# LangChain 的 Playwright loader 通过 CDP 连接
loader = PlaywrightURLLoader(
urls=["https://protected-site.com/docs"],
cdp_url="http://127.0.0.1:9222",
)
documents = loader.load()
print(documents[0].page_content[:500])
browser.close()6.5 与 Selenium 集成
如果你之前用的是 Selenium,CloakBrowser 也可以通过 CDP 桥接模式接入:
from cloakbrowser import launch
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 启动 CloakBrowser
browser = launch(headless=True, args=["--remote-debugging-port=9222"])
# Selenium 连接到 CDP
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(options=options)
driver.get("https://protected-site.com")
print(driver.title)
driver.quit()
browser.close()从 Selenium 迁移时需要注意:通过 CDP 连接后,Selenium 不能再启动新的浏览器实例,只能控制已经启动的 CloakBrowser 实例。建议把浏览器生命周期管理交给 CloakBrowser,Selenium 只负责页面操作。
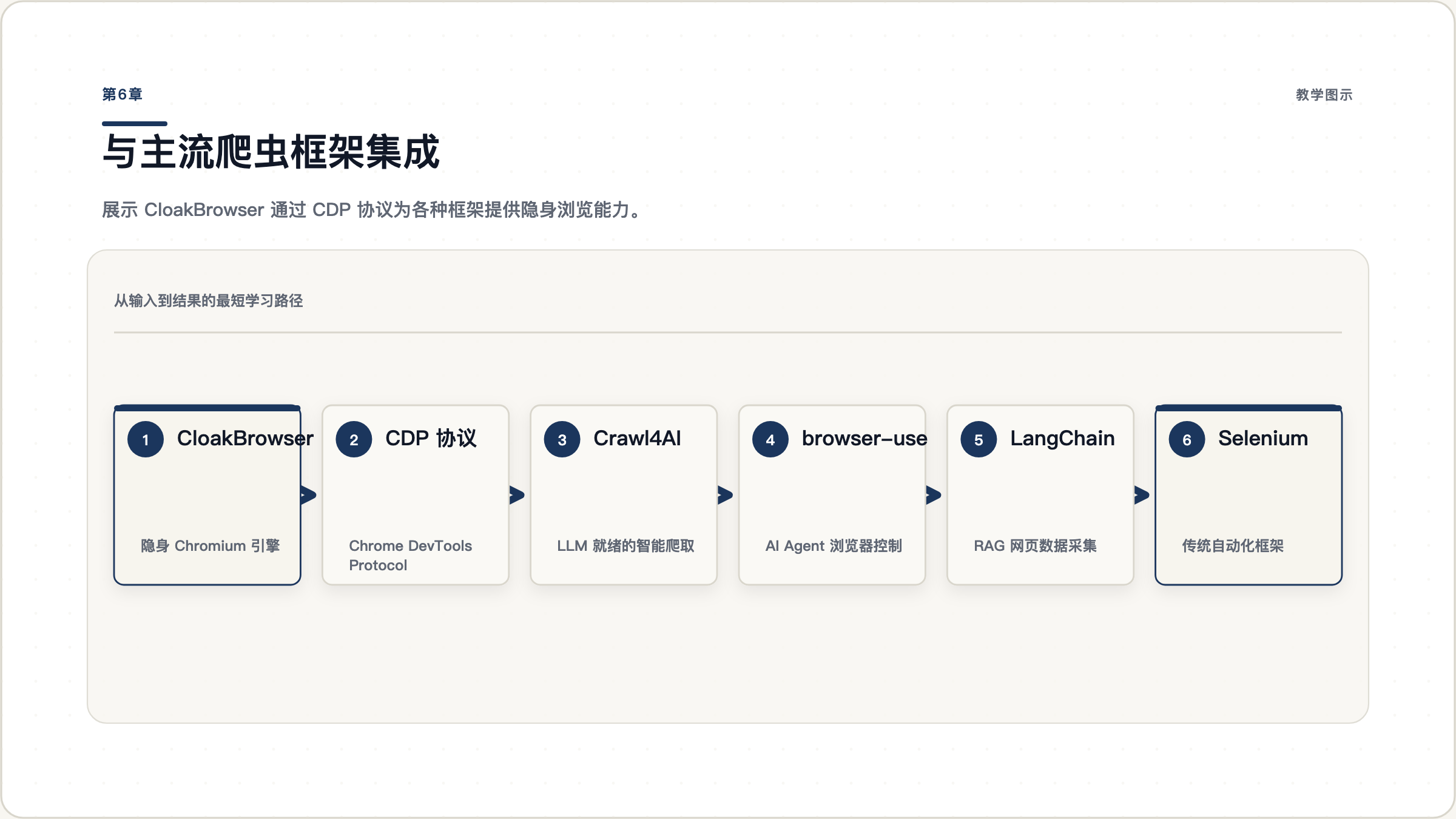
图 6.1: CloakBrowser 作为底层隐身引擎,通过 CDP 协议为各种框架提供隐身浏览能力。所有框架共享同一个隐身浏览器实例。
练习: 选择一个你项目中正在使用的框架(Crawl4AI、browser-use、LangChain 或 Selenium),完成 CloakBrowser 的 CDP 连接集成,测试能否成功访问之前被封锁的页面。
第7章 最佳实践与合规边界
技术能力到位了,但生产环境的爬虫要稳定运行,还需要考虑代理策略、性能优化、错误处理和合规性。
7.1 稳定性最佳实践
代理轮换策略 不要盲目地随机切换代理。每次切换代理 IP,指纹一致性的”故事”就变了。更好的做法是:
- 每个代理 IP 维持一个会话,在会话内完成尽可能多的任务
- 切换代理时同步更新 GeoIP 设置(CloakBrowser 的
geoip=True会自动处理) - 使用粘性会话(sticky session)代理,避免每次请求换 IP
会话管理 对于需要登录的网站,使用 launch_persistent_context() 保持登录状态。频繁登录本身就可能触发风控。一旦建立了一个可信的会话,尽量复用它。
错误重试与降级 遇到封锁时不要立即重试。等待一段时间,可能需要换一个新的代理 IP 和全新的浏览器上下文。
from cloakbrowser import launch
import time
def scrape_with_retry(url, max_retries=3):
for attempt in range(max_retries):
try:
browser = launch(headless=True, proxy=get_next_proxy(), geoip=True)
page = browser.new_page()
page.goto(url, timeout=30000)
if "captcha" in page.title().lower():
raise Exception("遇到验证码")
return page.content()
except Exception as e:
print(f"第 {attempt + 1} 次尝试失败: {e}")
time.sleep(30 * (attempt + 1)) # 指数退避
finally:
browser.close()
return None7.2 性能优化
并发控制 CloakBrowser 是完整的 Chromium 浏览器,每个实例占 200-500MB 内存。合理控制并发数:
import asyncio
from cloakbrowser import launch_async
async def scrape(url):
browser = await launch_async(headless=True)
page = await browser.new_page()
await page.goto(url)
content = await page.content()
await browser.close()
return content
async def main():
urls = [...] # 目标 URL 列表
semaphore = asyncio.Semaphore(5) # 最多 5 个并发
async def limited_scrape(url):
async with semaphore:
return await scrape(url)
results = await asyncio.gather(*[limited_scrape(url) for url in urls])资源拦截 对于数据采集场景,可以拦截图片、CSS、字体等非必要资源,显著提升加载速度:
from cloakbrowser import launch
browser = launch(headless=True)
page = browser.new_page()
# 拦截非必要资源
page.route("**/*.{png,jpg,jpeg,gif,svg,css,woff,woff2}", lambda route: route.abort())
page.goto("https://example.com")7.3 合规与道德边界
技术可以实现,不代表应该做。爬虫的合规边界涉及多个层面:
尊重 robots.txt:虽然 robots.txt 没有法律强制力,但它是网站表达意愿的标准方式。尊重它是基本的网络礼仪。
速率限制:即使你能快速爬取,也要控制频率。合理的标准是:不给目标服务器带来显著负担。一个简单的原则是,你的爬取频率不应超过一个正常用户手动浏览的频率。
个人数据保护:爬取包含个人信息的内容(姓名、联系方式、位置等)可能涉及隐私法律。特别是 GDPR、中国《个人信息保护法》等法规对个人数据的采集和处理有严格要求。
合理使用原则:爬取公开数据用于个人学习、研究通常问题不大。但大规模爬取商业数据用于竞争目的,可能涉及不正当竞争法律风险。
| 场景 | 合规风险 | 建议 |
|---|---|---|
| 爬取公开学术数据用于研究 | 低 | 注明来源即可 |
| 爬取电商价格用于个人比价 | 低 | 控制频率,不商业使用 |
| 爬取公开数据构建竞品产品 | 中 | 咨询法律意见 |
| 爬取用户生成内容(评论、帖子) | 中-高 | 注意隐私和版权 |
| 爬取需要登录才能访问的内容 | 高 | 违反 ToS 风险,需法律评估 |
| 爬取个人身份信息 | 很高 | 强烈不建议,可能违法 |
声明
本节不构成法律建议。在进行任何大规模爬取前,请咨询专业法律人士。
7.4 检测与反检测的军备竞赛
反爬技术在持续进化。今天有效的方案,明天可能就失效了。CloakBrowser 的源码级补丁方案是目前最深入的反检测技术,但它不是银弹。
更可持续的策略是:
- 构建可维护的爬虫架构:把反检测逻辑和业务逻辑解耦,方便快速切换反检测方案
- 监控成功率:记录每次请求的结果,及时发现检测策略的变化
- 多方案备份:准备多种反检测方案,当一种失效时可以快速切换
- 关注社区动态:反检测技术社区(GitHub、论坛)会及时分享最新的检测和绕过技术
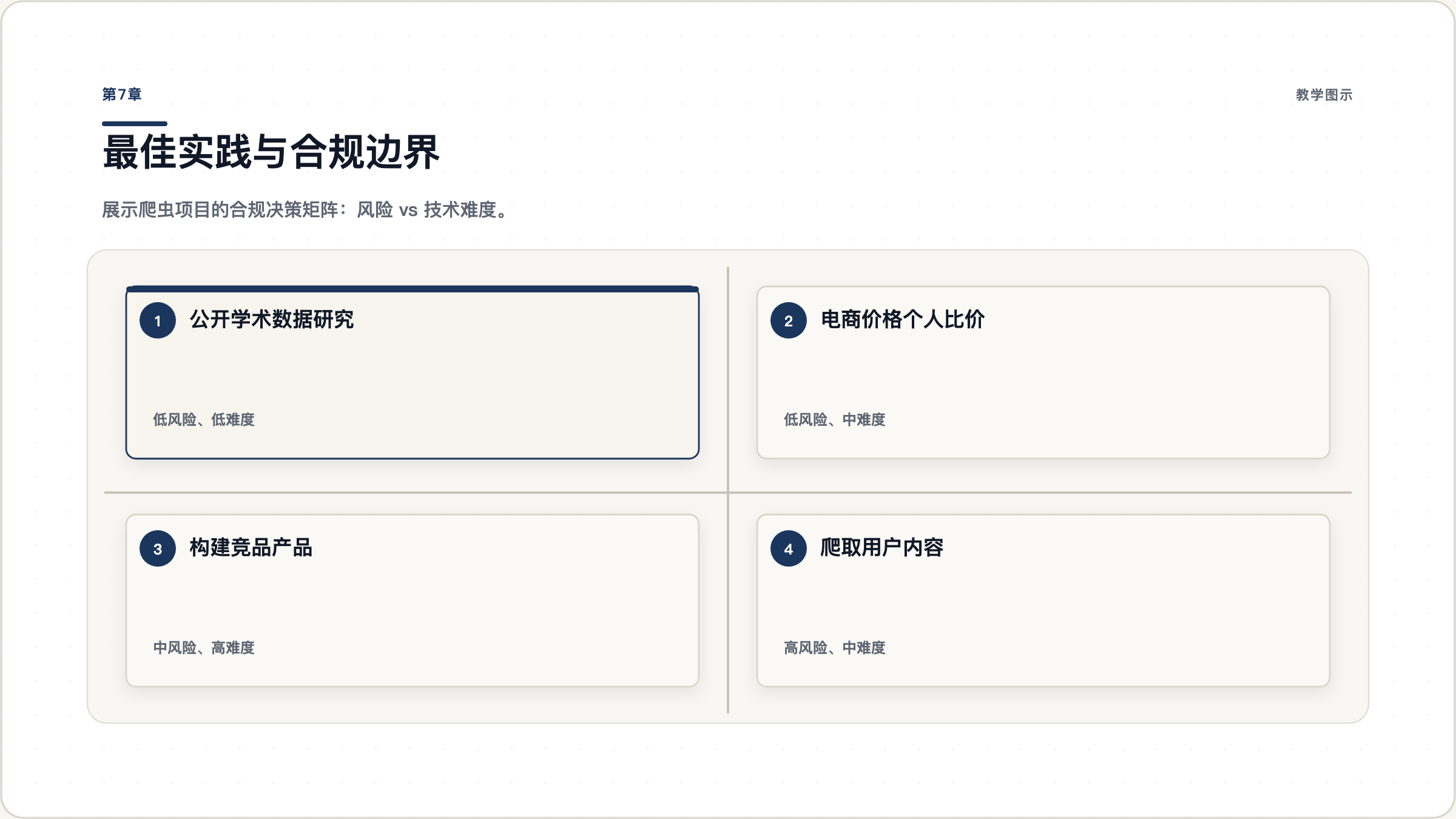
图 7.1: 爬虫项目的合规决策矩阵。纵轴是合规风险,横轴是技术难度。优先选择左下角(低风险、低难度)的场景,谨慎对待右上角。
练习: 审视你当前的爬虫项目,对照上面的合规矩阵,列出需要改进的地方。重点关注:是否尊重 robots.txt?频率是否合理?是否涉及敏感数据?
参考资料
- CloakBrowser GitHub 仓库 — 隐身 Chromium 浏览器,源码级反检测
- Playwright 官方文档 — 浏览器自动化框架
- Cloudflare Bot Management 文档 — 现代反爬系统工作原理
- FingerprintJS — 开源浏览器指纹识别库
- undetected-chromedriver — Selenium 反检测方案
- puppeteer-extra-plugin-stealth — Puppeteer 反检测插件
- BrowserScan — 浏览器指纹和自动化检测服务
下一步学习建议
- 深入 Playwright API:CloakBrowser 的 API 完全兼容 Playwright,掌握 Playwright 能让你更高效地使用 CloakBrowser
- 代理策略优化:研究住宅代理的采购和管理策略,好的代理是成功的一半
- 分布式爬虫架构:学习 Scrapy、Crawlee 等框架的分布式调度机制,构建大规模爬虫系统
- 数据清洗与存储:爬取只是第一步,高效的数据管道同样重要